On the Role of Optimization in Double Descent: A Least Squares Study.Double Descent Part 2: A Mathematical Explanation Brent Werness & Jared Wilber, December 2021 .We provide visual intuition using polynomial regression, then mathematically analyze double descent with ordinary linear regression and identify three interpretable factors .We argue that double descent is a consequence of the model first learning the noisy data until interpolation and then adding implicit regularization via over .Deep Double Descent for Time Series Forecasting: Avoiding Undertrained Models.In this paper, we propose a novel personalized federated learning method called Personalized Federated Learning with Double Descent (pFeD3) to mitigate the impact of data heterogeneity.5月10日上午10 点 ,统计与数据科学学院 “统院同行者”系列讲座 统计学类专业学习漫谈第一讲 正式开讲。In this lecture, we explain the concept of double descent introduced by [4], and its mechanisms.We find that double descent can be attributed to distinct fea- tures being learned at different scales: as fast-learning features overfit, slower- learning features start to fit, .To understand under what conditions and why double descent occurs at the interpolation threshold in linear regression, we’ll study the two parameterization regimes. By looking at a number of examples, section 2 intro-duces . 时间: 13:30 – 15:05, every Monday,Wednesday, 3/14/2022 – 6/8/2022. 地点: 1118&Zoom ID:638 227 8222,密码:BIMSA. Their performance is heavily influenced by the size of the neural network.In this study, we revisit the phenomenon of double descent and demonstrate that its occurrence is strongly influenced by the presence of noisy data.本专栏从一个半路出家的管理学外行(毫无统计和科研基础)视角出发,根据个人亲身经历去做一些经验分享和问题探讨,也是对我过去三年逐渐形成自己的科研习惯,走过的弯路等的一个总结和回顾。 Part 1 is available here. By looking at a number of examples, section 2 introduces inductive biases that appear to have a key role in double descent by selecting, among the multiple interpolating solutions, a smooth empirical risk minimizer.On Double Descent in Reinforcement Learning with LSTD and Random Features. The first section sets the classical statistical learning framework and introduces the double descent phenomenon.
深度学习中的双下降现象
In this first part, however, we will hold the number of parameters constant and change the sample size.One of the most fascinating findings in the statistical/machine learning literature of the last 10 years is the phenomenon called double descent. 为了解决本科年级同学对专业学习以及学习方法上的困惑与 疑问 ,本次讲座特别邀请了学院副教授李忠华老师带来以 疑问 ,本次讲座特别邀请了学院副教授李忠华 While some theoretical explanations have been proposed for this phenomenon in specific contexts, an accepted theory to account for its occurrence in deep learning .统计学习XYZ. 위 그림을 보면, ResNet18을 CIFAR10,100 데이터셋에 대해, 모델의 크기 를 키워가며 실험을 진행했고, 모든 경우에서 Double Descent 현상을 볼 수 있었습니다.Usually, in the double descent literature, the focus is on the number of predictors. 为优化实验班培养体系,开拓本科生统计学思维,继续深化统计学专业教育教学改革,培养创新型统计人才,我院于2017年12月19日组织“名师讲堂”系列活动第五讲,并邀请濮晓龙教授做题为“漫谈应用统计”专题讲座。
Deep Double Descent 현상
Empirically it has been observed that the performance of deep neural networks steadily improves as we increase model size, contradicting the classical view on overfitting and . 在统计推断中,经验贝叶斯方法是非常重要的工具之一,能够帮助我们在缺乏先验分布的情况下做出推断,有时有些场景下的 .在近日发表的一篇论文中,来自哈弗大学的研究者证明了在CNN、ResNet和transformer中会出现double descent(二次下降)现象:随着模型增大、数据增多或训练时间延长,模型性能先提高,接着会变差,继而再次提高。费舍尔爵士 (Sir Ronald Fisher .In this tutorial, we explain the concept of double descent and its mechanisms.
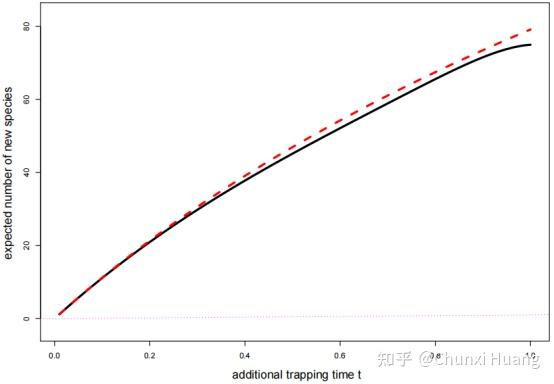
In this paper, we present a comprehensive framework that provides a unified view of these .Our goal in this tutorial is to explain why double descent occurs in an approachable manner, without resorting to advanced tools oftentimes employed to analyze double .“名师讲堂”第五讲: 漫谈应用统计. 组织者: 宋丛威.VC Theoretical Explanation of Double Descent. While in supervised .Using insights from theory, we give two methods by which epochwise double descent can be removed: one that removes slow to learn features from the input and reduces generalization performance, and another that instead modifies the training dynamics and matches or exceeds the generalization performance of standard training.数学与统计学院院长赵会江主持报告会。
漫画统计学读书笔记视频(完结)共计33条视频,包括:统计概念大串联 part1、统计概念大串联 part2、统计概念大串联 part3等,UP主更多精彩视频,请关注UP账号。 来源: 03-14.近日,哈佛大学Preetum Nakkiran等研究者与人工智能研究组织OpenAI的研究者Ilya Sutskever最新研究发现,包括卷积神经网络(Convolutional Neural .Recent studies have uncovered intriguing phenomena in deep learning, such as grokking, double descent, and emergent abilities in large language models, which challenge human intuition and are crucial for a deeper understanding of neural models. 考虑线性模型中的不同 . 머신러닝에서는 모델 크기, 데이터 크기, 또는 학습 횟수가 증가함에 따라 정확도가 향상되며, 모델이 과학 습하기 시작하면 테스트 데이터에 대한 정확도가 떨어집니다.In this work, we analytically dissect the simple setting of ordinary linear regression, and show intuitively and rigorously when and why double descent occurs, . There has been growing interest in generalization performance of large multilayer neural networks that can be trained to achieve zero training error, while generalizing well on test data. We show that a variety of modern deep learning tasks exhibit a double-descent phenomenon . In particular, given the sample, whether the neural network should be wider or deeper is the main focus of attention. The article builds on the cubic .通常通过正则化来避免这种结果。We provide visual intuition using polynomial regression, then mathematically analyze double descent with ordinary linear regression and identify ., and was extensively explored after.We demonstrate that double descent occurs on real data when using ordinary linear regression, then demonstrate that double descent does not occur when any of the three factors are ablated.LG]
Deep Double Descent: Where Bigger Models and More Data Hurt
Deep learning models, particularly Transformers, have achieved impressive results in various domains, including time series forecasting. A Sketch of the Mathematics. Temporal Difference (TD) algorithms are widely used in Deep Reinforcement Learning (RL). Deep Double Descent는 거기서 .虽然这种行为似乎相当普遍,但研究者仍未完全理解为什么 . While existing time series literature primarily focuses on model architecture modifications and data augmentation techniques, .
读《漫谈现代统计四大天王》
또, 이러한 현상은 label noise 가 . 这个实验的效果比较好,可以展示双下降的现象. This approach looks deeper into family lineage, extending beyond immediate parents to British grandparents.Cite as: arXiv:2303. According to the British Nationality Act of 1981, the usual basis for .
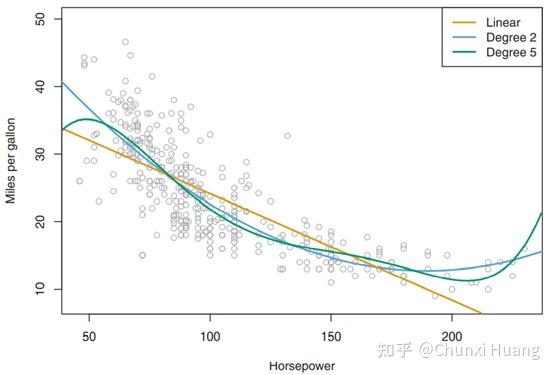
We use this understanding to shed light on recent observations in nonlinear models concerning superposition and double descent.We focus on the phenomenon of double descent in deep learning wherein when we increase model size or the num-ber of epochs, performance on the test set initially improves (as expected), then . 统计学家利用收集到的数据进行统计学习建模,学习出的模型就能够根据父母 . Section 1 sets the classical statistical learning framework and introduces . 陈松蹊从环境大数据入题,介绍了环境大数据在 .
Hello,大家好,从本期开始将会开设一个新的专栏,科研漫谈。
Understanding the Double Descent Phenomenon in Deep Learning
This double descent phenomenon in deep learning was discovered in 2018, see the original paper by Belkin et al. 以及如何才能展示出较完美的双下降曲线.Deep Double Descent: Where Bigger Models and More Data Hurt. 主讲人: 宋丛威.British citizenship via Double descent is a much complex and niche route designed for those aiming to claim British citizenship through a grandparent. 举个很简单的例子,根据长期的观察,人们发现子女和父母的身高之间存在一定的定性关系。
British Citizenship by Double Descent
Double descent provides an indication that even though models that pass through every training data point are indeed overfitted, the structure of the resulting network forces the interpolation to be smooth and .We show that the double descent phenomenon occurs in CNNs, ResNets, and transformers: performance first improves, then gets worse, and then improves again with increasing model size, data size, . 统计学习XYZ是课程“统计学习ABC”的续集。
Papers with Code
卡尔·皮尔逊 (1857~1936) 罗纳德. 下面我们讨论不同因素对曲线的影响.与此不同的是,经验贝叶斯方法中先验分布并不提前给出,而是从获得的观测数据中去估计,这恰好印证了其命名中的“经验”二字。
Double Descent Demystified
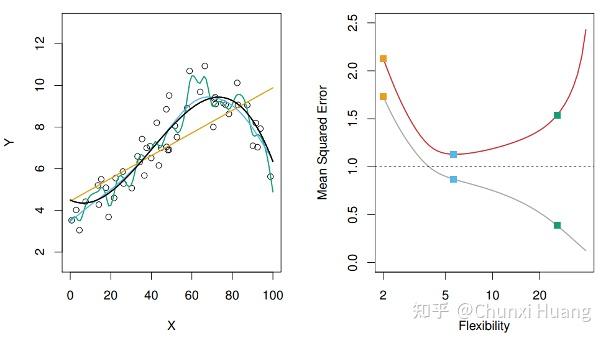
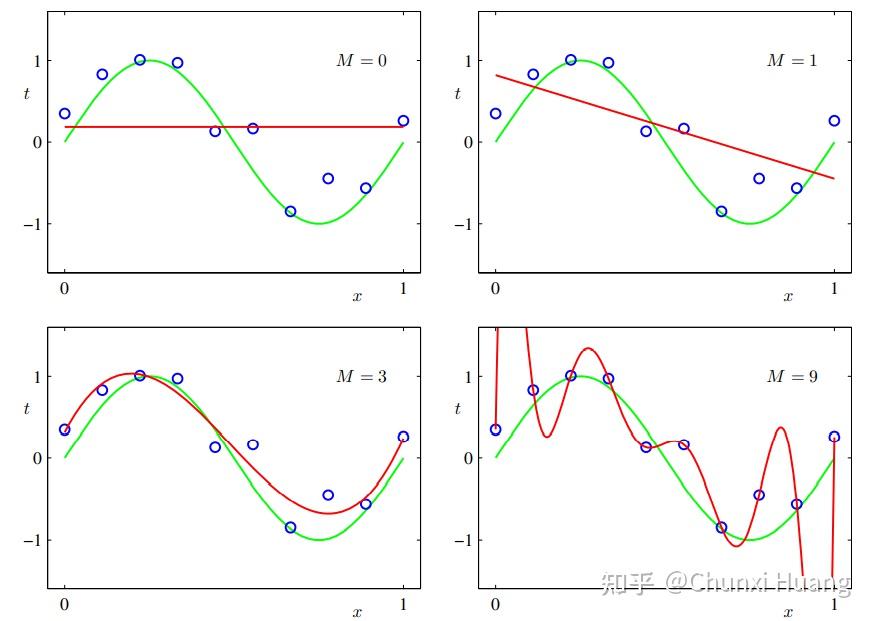
The first section sets the classical statistical learning framework and introduces the double descent phenomenon.Double descent curve. 副校长李资远为其颁发“珞珈讲坛”纪念证书。 This regime is known as ’second descent‘ and it appears to contradict the conventional view that optimal model . By looking at a number of examples, section 2 introduces inductive biases that appear to have a key role in double descent by .Meet the double descent phenomenon in modern machine learning: what it is, how it relates to the bias-variance tradeoff, the importance of the interpolation regime, and a theory of what lies behind. For some reason, extremely over .Yann LeCun explains the Double Descent phenomenon in Machine Learning. Figure 1: The classical risk curve arising from the bias-variance trade-off and the double descent risk curve with the observed modern interpolation regime. 举个很简单的例子,根据长期的观察,人们发现子女和父母的身高之间存在 .In our previous discussion of the double descent phenomenon, we have made use of a piecewise linear model that we fit to our data.新闻网讯 ( 通讯员刘伟、刘宇阳 ) 5月18日下午,中国科学院院士、北京大学讲席教授陈松蹊做客珞珈讲坛第378讲,作题为“数据实验与统计分析”的学术报告。Section 1 sets the classical statistical learning framework and introduces the double descent phenomenon.deep learning is an active field of research, and we focus on the double descent phenomenon, first demonstrated by [3] and illustrated in Figure 1. Our approach decouples the up-dates of personalized models from the main FL process, allowing for personalized solutions tailored to each client.Double descent presents a counter-intuitive aspect within the machine learning domain, and researchers have observed its manifestation in various models and tasks. 모델의 크기 를 키우게 되면, Double Descent현상이 일어납니다.Deep Double Descent. 可以操控的因素与 U curve 中提及的类似. 要展示双下降, 我们在 U curve 的基础上, 增加 (与模型变量相关的) 变量的个数. In our previous discussion of the double descent phenomenon, we have made use of a piecewise linear model that we fit to our . Ilja Kuzborskij, Csaba Szepesvári, Omar Rivasplata, Amal Rannen-Triki, Razvan Pascanu. Double Descent: A Mathematical Explanation Deepen your understanding of the double descent phenomenon.统计学习做的就是这么一件事:基于数据构建模型并且用模型对数据进行预测和分析。 An overview of . Note – this is part 2 of a two article series on Double Descent.

David Brellmann, Eloïse Berthier, David Filliat, Goran Frehse.
统计学类专业学习漫谈开讲
This may seem a somewhat strange . 本课程主要介绍统计学习的高级模型和算法,以及 .
Tutorial on the Double Descent Phenomenon in Deep Learning
《漫谈现代统计四大天王》是勤学派公众号中的一系列的随笔, 这个系列随笔主要记述波澜壮阔、精彩纷呈的统计世界里那些令笔者印象深刻的故事与传奇; 试图去理解和还原现代统计的逻辑与思想s.Autor: Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, Ilya Sutskever
Deep double descent
While most attention has naturally been given to the deep-learning setting, double descent was shown to emerge more generally across non-neural models: .Model-Wise Double Descent.
- Teuerste stürme deutschlands 2024 – die teuerste stürme deutschlands
- Augenarzt in euskirchen, deutschland – augenarzt euskirchen veybachstr
- Plastiktüten pro und contra | plastiktüten verbot händler
- Inspiration for creating the coolest custom roblox character | coole avatars in roblox
- Favicon , favicon.cc
- 35 squirrel monkey facts: all 5 saimiri species – saimiri sciureus monkey
- Theater rotenburg wümme, rollentausch rotenburg 2022
- Auslandsaufenthalt nach der ausbildung oder dem studium – studiengänge im ausland finden
- The marriage plot | eugenides marriage plot