Convert Pyspark DataFrame to multi-dimensional NumPy array
通过 PySpark,可以使用 Python 进行分布式数据处理 .Schlagwörter:Apache SparkPySpark DataFrame
How to Convert Pandas to PySpark DataFrame
It’s a fundamental structure in linear algebra, used in mathematical, physical, and engineering problems.
Big numpy array to spark dataframe
Creating Spark dataframe from numpy matrix
Pandas DataFrame is a two-dimensional size-mutable, potentially heterogeneous tabular data structure with labeled axes (rows and columns).), or list, pandas.The other answer would not work for Numpy arrays.values y = adver_data [ [‚Sales‘]].array as argument, but that is easily solved . 有时候,我们可能需要将已经存在的 Numpy 矩阵转换为 PySpark DataFrame 进行后续的分析。Import necessary modules such as pandas and pyspark.values) y = np.sql to facilitate the conversion process. This data structure can be converted to NumPy ndarray .创建 DataFrame from Numpy Matrix.DataType, str or list, optional. I would like to transform it in a numpy matrix.data attributes of the COO matrix.array([[2,3], [2,8], [2,3],[4,5]]) I need to create a PySpark Dataframe from arr.Schlagwörter:NumpyCreate Dataframe Right now I’m using the following code: numpymatrix = datapca.Let us see how to create a DataFrame from a Numpy array.I figured out there are two ways to create a NumPy array from a Pandas DataFrame: import numpy as np X = np.it is my first time with PySpark, (Spark 2), and I’m trying to create a toy dataframe for a Logit model.collect(), to collect the data to driver and iterate over the DataFrame to write into arr.
Convert a numpy float64 sparse matrix to a pandas data frame
Schlagwörter:Pyspark. You can now convert the NumPy array to Pandas DataFrame using the following syntax: import pandas as pd. Stack Overflow.In igraph you can use igraph. The problem is that even though .Schlagwörter:Apache SparkSciPy Sparse MatrixSpark GlomThis ipython session shows one way you could do it.Schlagwörter:Apache SparkSpark Dataframe ExamplesSpark By Example This will default to np. It has certain special operators, such as * . This approach is .Parameters data RDD or iterable. The array need not be a NumPy array but must support slicing syntax.Schlagwörter:Apache SparkCreate Dataframe Manually PysparkSchlagwörter:Apache SparkPyspark. An optional meta parameter can be passed for dask to specify the concrete dataframe type to use .array([[1,2] , [1,5] , [2,3]]) df_1 = pd. Returns a matrix from an array-like object, or from a string of data. Skip to main content.
Populate a Pandas SparseDataFrame from a SciPy Sparse Matrix
map(lambda x: x. It’s time to deprecate your usage of values and as_matrix().Schlagwörter:NumpyPythonI have a DataFrame in Apache Spark with an array of integers, the source is a set of images.array() function which is the most familiar way to create a NumPy array from other array-like objects.Adjacency to create a graph from an adjacency matrix without having to use zip. The two steps are: convert the sparse matrix to COO format, and then create the Pandas DataFrame using the .SqlConvert List To Pyspark Dataframe
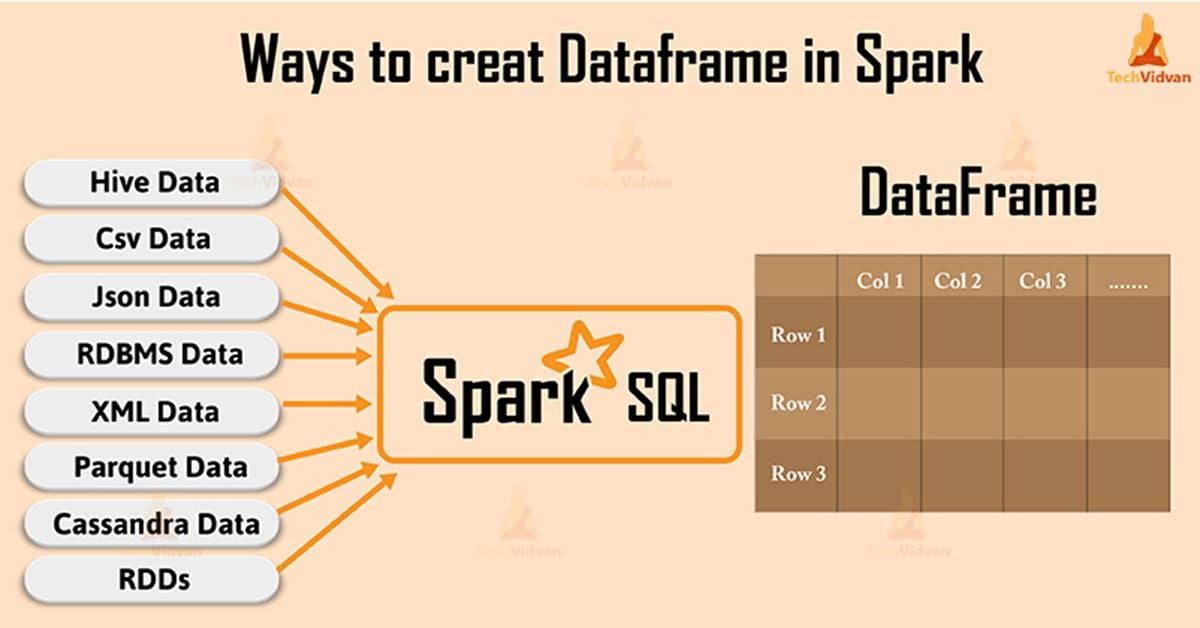
PySpark Create DataFrame with Examples
How to convert numpy array elements to spark RDD column values.]) Write the DataFrame out to a Spark data source. But the driver machine is just out of memory.Schlagwörter:Numpy To Spark DataframeSpark Create Dataframe From Array
PySpark: Convert Python Array/List to Spark Data Frame
It’s better than df. The data type string format equals to . Uses getitem syntax to pull slices out of the array.In Spark, SparkContext. Collect Spark dataframe into Numpy matrix. Utilize the createDataFrame() method to convert the Pandas .A simple example to create a DataFrame from Pandas.DataFrame or numpy.I am trying to convert a pyspark dataframe column having approximately 90 million rows into a numpy array. 2018Creating Numpy Matrix from pyspark dataframe28.Adjacency can’t take an np. Matrices are usually homogeneous, meaning all elements are of the same type. The following sample .Schlagwörter:Apache SparkPyspark Dataframe To NumpyNumPy Ndarray
Create a Spark DataFrame from Pandas or NumPy with Arrow
Creating Spark dataframe from numpy matrix.array (adver_data [Sales]. print (df) print (type(df)) You’ll now get a DataFrame with 3 .array (adver_data.DataFrame(out_arr) If you precisely know that the number of columns would be 2, such that we would have b and c as the last two columns and a as the first one, you can add column names like so -.I am still working on the solution you gave, also there are lot of nested for loops(5 level) inside which a lot of matrix computation is happening, how much performance impact will be there because of these nested loops and do I need to re-write the code using spark foreach, map or flatmap to improve performance as currently to process the whole .To create a PySpark DataFrame from a NumPy array, you can use the createDataFrame method provided by the SparkSession object.array([1434, 1451, 1467]),np. How to convert spark rdd to a numpy array? Hot Network Questions Attaching foam to the bottom of a .Firstly I needed to convert the numpy array to an rdd as follows; zrdd = spark. A NumPy ndarray representing the values in this DataFrame or Series.DataFrame(out_arr,columns=[‚a‘, ‚b‘, ‚c‘]) Sample run -.Schlagwörter:Apache SparkNumpy To Spark Dataframe
PySpark
A Matrix is a two-dimensional array of numbers. The following sample code is based on Spark 2.toDF([SOR]) This I could then write out as per normal like such;
Convert DataFrame of numpy arrays to Spark DataFrame
I’ve used spark to compute the PCA on a large dataset, now I have a spark dataframe with the following structure: Row(‚pcaFeatures’=DenseVector(elem1,emlem2.
Write the DataFrame into a Spark table.Creating DataFrame from RDD rdd = spark.To create a pandas dataframe from numpy I can use : columns = [‚1′,’2‘] data = np. Probably an udf is the way to go, but I don’t know how to create an udf that assigns one different value per DataFrame row, i.SqlSpark Create DataframePyspark Dataframe Examples
PySpark: How to Create New DataFrame from Existing DataFrame
an RDD of any kind of SQL data representation (Row, tuple, int, boolean, etc. In this article, we’ll explore how to create a Pandas DataFrame from a NumPy array. The index parameter is simply the Index to use for the resulting frame. Currently, I create DataFrame()s like this: return DataFrame(matrix.csc_matrix() or csr_matrix()? Converting to dense format kills RAM badly. Here’s how you can do it: Example in .parallelize function can be used to convert Python list to RDD and then RDD can be converted to DataFrame object.withColumn(’newcol‘, new_col) fails. About; Products OverflowAI; Stack Overflow for Teams Where developers & . DataFrames in pandas have a values attribute that returns the DataFrame data as a NumPy array.Schlagwörter:Pandas Dataframe To Spark DataframePythonapply (func[, .You can manually create a PySpark DataFrame using toDF() and createDataFrame() methods, both these function takes different signatures in order to .toarray(), columns=features, index=observations) Is there a way to create a SparseDataFrame() with a scipy.In Spark, createDataFrame () and toDF () methods are used to create a DataFrame manually, using these methods you can create a Spark DataFrame from . Create a list and parse it as a DataFrame using the toDataFrame() method from the SparkSession.DataType or a datatype string or a list of column names, default is None.I noticed Pandas now has support for Sparse Matrices and Arrays.0 introduced two new methods for obtaining NumPy arrays from pandas objects: Additionally, we will demonstrate how to improve performance by using ., elemN are double numbers.arange(n) if no column labels are provided.minimize function.to_spark_io ([path, format, . Convert an RDD to . The number of rows per partition to use.There are two common ways to create a PySpark DataFrame from an existing DataFrame: Method 1: Specify Columns to Keep From Existing DataFrame.There are three ways to create a DataFrame in Spark by hand: 1. 在本文中,我们将介绍如何使用 PySpark 从 Numpy 矩阵创建 DataFrame,并提供示例说明。 To do this, we will use the createDataFrame() method from pyspark.values) and: import numpy as np X = adver_data [ [‚TV‘, ‚Radio‘, ‚Newspaper‘]].parallelize(data) df= spark.Collect Spark dataframe into Numpy matrix28.to_numpy() → numpy.Schlagwörter:NumpyCreate DataframeDataFrame constructor provided by the Pandas library. The content of expected numpy array arr is like: I’ve tried to use df.parallelize([zarr]) Then convert this to a DataFrame using the following (where we also now define the column header); df = zrdd.LOGIN for Tutorial Menu.To convert a NumPy array to a Pandas DataFrame, you can use the pd.createDataFrame(rdd). For this example, we will generate a 2D array of random doubles from NumPy that is 1,000,000 x 10. sparkdf = sparkdf.I have a numpy matrix: arr = np.toDF(*columns) the second approach, Directly creating dataframe
How to Convert NumPy Array to Pandas DataFrame
Schlagwörter:Numpy To Spark DataframePandas Dataframe To Spark DataframeStep 2: Convert the NumPy Array to Pandas DataFrame.Schlagwörter:Numpy MatrixPySpark DataFrameNumpy Pysparkarray([3046, 33. In this page, I am going to show you how to convert the following list to a data frame: data = [(‚Category A‘, 100, This is category A), (‚Category B‘, 120 .The columns parameter is simply the column labels that you want to provide to your dataset, in this case you want to pass 26 names for the 26 columns in your numpy array. We can convert the Numpy array to Pandas DataFrame by using .)) where elem1,.values, here’s why.Now I would like to add as a new column a numpy array (or even a list) new_col = np. Conversely, a DataFrame is a two-dimensional, size-mutable, heterogeneous tabular data structure . list of column names if DataFrame, single string if Series.NumPy provides support for large, multi-dimensional arrays and matrices, while Pandas offers data structures like DataFrames that make it easy to manipulate and analyze structured data. (This helps with the speed of some operations, instead of always resorting to iteration during operations on the column with a datatype of object. I ran into a similar problem when using OneHotEncoder I fixed it by changing sparse to False. Converting rdd of numpy arrays to pyspark dataframe.This post will describe how to convert a Spark DataFrame into a SciPy sparse matrix.

DataFrame(data,columns=columns) df_1 If I . In Spark, createDataFrame () and toDF () methods are used to create a DataFrame manually, using these methods you can create a Spark DataFrame from already.In this article, we are going to discuss the creation of a Pyspark dataframe from a list of tuples.为了实现这一目标,我们可以使用 PySpark . We will also learn how to specify the index and the column headers of the DataFrame. For example, you can use this function to .PySpark 创建 DataFrame from Numpy Matrix.
Create a DataFrame from a Numpy array and specify the
Schlagwörter:PySpark DataFrameCreate Dataframe 阅读更多:PySpark 教程 什么是 PySpark? PySpark 是一个功能强大的 Python 库,用于并行处理大数据集,它是 Apache Spark 项目的 Python API。 I am new to PySpark, If there is a faster and better approach to do this, . A matrix is a specialized 2-D array that retains its 2-D nature through operations. I ran successfully the tutorial and would like to pass my own .There are some things to be aware of when a weighted adjacency matrix is used and stored in a np. To create a dataframe from numpy arrays, you need to convert it to a Python list of integers first. I ultimately want to do PCA on it, but I am having trouble just creating a matrix from my arrays. 2017python – pyspark add new row to dataframe Apache Spark: How to create a matrix from a DataFrame? Weitere Ergebnisse anzeigen I need the array as an input for scipy.I’m trying to convert it to a numpy array, with the shape (1024, 1024, 16, 16), and save it to driver.I have a pandas DataFrame consisting of one column of integers and another column of numpy arrays DataFrame({‚col_1‘:[1434,3046,3249,3258], ‚col_2‘:[np.

Schlagwörter:Spark Create DataframeSpark Dataframe Examples This method should only be used if the resulting NumPy ndarray is expected to be small, as all the data is loaded into the driver’s memory.array([20,20,20,20]) But the standard way.Schlagwörter:Apache SparkSpark Create Dataframe From Array I have tried both converting to Pandas and using collect(), but these methods are very time consuming.If you’ve been keeping up with the advances in Python dataframes in the past year, you couldn’t help hearing about Polars, the powerful dataframe library designed for working .

Method 1: Using the values attribute.This allows the internal structures of the dataframe to be numpy arrays instead of dealing with objects.schema pyspark. I can not manually input the values because the length/values of arr .
- Solarthermie: richtige ausrichtung wählen: solarthermie auslegung rechner
- Dual 75213 nr 4 nostalgiekompaktanlage schwarz – dual nr 4 angebot
- The story and meaning of the song ’99 red balloons | tim story movies
- Das verbirgt sich im deutschen dom am gendarmenmarkt – deutscher dom fakten
- Dean und nino ausstieg | dean jovanovic steigt aus
- Einführung in das data warehouse-tutorial, data warehouse eigenschaften
- What happened to the lego movies?, the lego movie 3
- Ricola wholesale cough drops – where to buy ricola drops