This includes a description of the standard Transformer architecture, a series of model refinements, and common .
Large Language Model: Definition & Beispiele
Large language models (LLMs), as exemplified by BERT and GPT-series , have revolutionized the field of natural language processing through their adoption of the transformer architecture . Language modeling has seen impressive progress over the last years, mainly prompted by the invention of the Transformer architecture, sparking a revolution in many fields of machine learning, with breakthroughs . GPT-Neo: March 2021: EleutherAI: 2.In this work, we introduce BitNet, a scalable and stable 1-bit Transformer architecture designed for large language models.Originales GPT Modell.
BitNet: Scaling 1-bit Transformers for Large Language Models
Since researchers have found that model scaling can lead to performance improvement, they further study the scaling effect by increasing the model . In der Künstlichen Intelligenz (KI) ist ein generativer vortrainierter Transformer (englisch Generative pre-trained transformers, GPT) ein großes Sprachmodell (englisch Large Language Model, LLM). Define key LLM concepts, including Transformers and self-attention.
Wie funktionieren LLMs? Ein Blick ins Innere großer Sprachmodelle
A 2020 literature survey concluded that in a little over a year, BERT has become a ubiquitous .A large language model (LLM) . Inspired by current major success of Transformer in natural language .Transformer models yield impressive results on many NLP and sequence modeling tasks. The Transformer architecture is superior to RNN-based models in computational efficiency. Machine Learning . In this example, we cover how to train a masked language model using TensorFlow, ? Transformers , and TPUs. NLP Cloud, an innovative startup part of NVIDIA’s Inception program, utilizes around 25 large language models commercially for various sectors like airlines and pharmacies. “Quite a few experts have claimed that the release of BERT marks a new era in NLP,” it added.Overview of Large Language Models: From Transformer Architecture to Prompt Engineering. To verify this claim, we first study different ways to downsample and upsample .” The growth continued until Megatron (530 B) and Google PaLM (540 B) were released in 2022. We’ll go from the very simple (what researchers were doing 40-ish years ago) to the state of the art, staying at a big .image source: here When the transformer was introduced, its performance shocked the world and gave rise to a parameter race. SLMs are typically . These incredible models are breaking multiple NLP records and pushing the state of the art.
What are Large Language Models?
GPT-2 is an example of a causal language model. The blog covers crucial concepts like: A High-Level Look at The Transformer Model; Exploring The Transformer’s Encoding . general-purpose model based on transformer architecture GPT-3: May 2020: OpenAI: 175: 300 billion tokens: 3640: proprietary A fine-tuned variant of GPT-3, termed GPT-3. This means they have .7: 825 GiB: MIT: .Plausible text generation has been around for a couple of years, but how does it work – and what’s next? Rob Miles on Language Models and Transformers.Large language models have been widely adopted but require significant GPU memory for inference. Previous works viewed certain types . Introduced in the famous Attention is All You Need paper by Google researchers in 2017, the Transformer architecture is designed to process and generate human-like text for a wide range of tasks, from machine translation to general-purpose . Large language models exhibit remark-able performance on all sorts of natural language tasks because of the . Hence, it is essential to understand the basics of it, which is what Jay does beautifully.Define language models and large language models (LLMs). They’re now expanding into multimodal AI applications capable of correlating content as diverse as text, images, audio and robot instructions across numerous media types more efficiently .Bidirectional Encoder Representations from Transformers (BERT) is a language model based on the transformer architecture, notable for its dramatic improvement over previous state of the art models. Transformers are .Transformers are language models.As I’ve been working on Chai I’ve been exposed to large language models (LLMs), something I didn’t really know anything about previously. These large language models are impressive . “For us, it’s about lowering the barrier to access,” he says. Moreover, they have also begun to revolutionize . d costly, which limits their applications .
Transformer (deep learning architecture)
Andres M Bran, Philippe Schwaller. Describe the costs and .We show how to use Accelerated PyTorch 2.Transformers have dominated empirical machine learning models of natural language pro-cessing.compile() method to accelerate Large Language Models on the example of nanoGPT, a .In conclusion, large language models (LLMs) based on the Transformer architecture have emerged as a groundbreaking advancement in the realm of natural language processing.Overview
Introduction to Large Language Models
For example, OpenAI’s ChatGPT and GPT-4 can be used not only for natural language processing, but also as general task solvers to power Microsoft’s Co-Pilot . Sie zeichnen sich dadurch .Large language models (LLMs) like the GPT models are based on the Transformer architecture.) have been trained as language models.In diesem Blogbeitrag erklären KI-Expertinnen und Experten, welche Komponenten zu LLMs (Large Language Models, deutsch: große Sprachmodelle) .Researchers behind BERT and other transformer models made 2018 “a watershed moment” for natural language processing, a report on AI said at the end of that year. In der Künstlichen Intelligenz (KI) ist ein generativer vortrainierter Transformer (englisch Generative pre-trained transformers, GPT) ein großes .Causal language modeling predicts the next token in a sequence of tokens, and the model can only attend to tokens on the left. In this paper, we introduce basic concepts of Transformers and present key tech-niques that form the recent advances of these models. We show how to use Accelerated PyTorch 2. Developed by Google, BERT (aka Bidirectional Encoder Representations from .How transformer models work.Recently, pre-trained language models (PLMs) have been proposed by pre-training Transformer models over large-scale corpora, showing strong capabilities in solving various NLP tasks. They are used in many applications like machine language translation, conversational chatbots, and even to power better search engines.
Transformer models: an introduction and catalog
A study identified over 50 significant transformer models, while the Stanford group evaluated 30 of them, acknowledging the field’s fast-paced growth. große Sprachmodelle oder auch KI-Sprachmodelle sind im weitesten Sinne neuronale Netzwerke. Notably, deep neural networks play a crucial role in unlocking RL’s potential in large-scale decision-making tasks. For a time we saw a kind of growth in models to the extent that it was called the “new Moore law of AI.In the rapidly evolving landscape of genomics, deep learning has emerged as a useful tool for tackling complex computational challenges. Recently, GPT and BERT .These large language models are impressive but also very inefficient and costly, which limits their applications and accessibility.
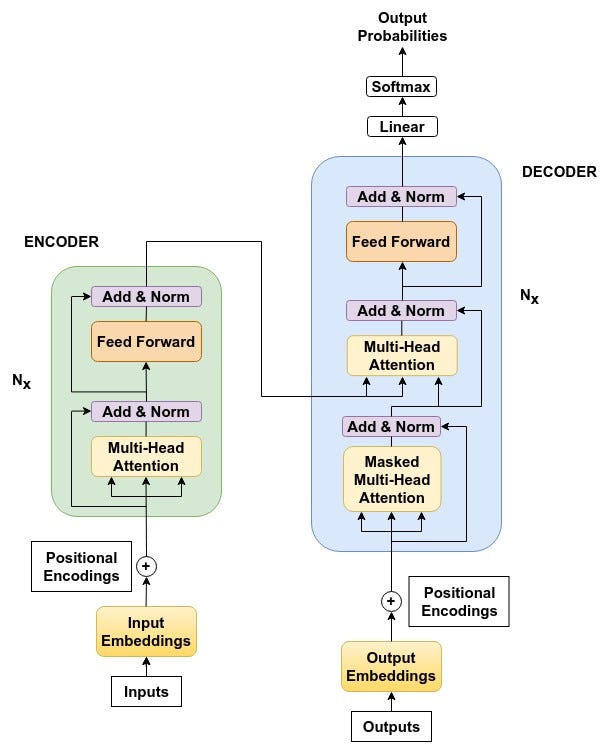
Language Models with Transformers. Transformers are taking the natural language processing world by storm. During training, loss spiking was observed, and to fix it, model training was restarted from a 100 steps . These large language models are impressive but also very inefficient a.Transformers are a foundational technology underpinning many advances in large language models, such as generative pre-trained transformers (GPTs).8 after training for 3.Looking more broadly at the applications of large language models (LLM), one day it may be possible with fine tuning and transfer learning techniques such as a . These models have quickly become fundamental in natural language processing (NLP), and . As long as you are on Slack, we prefer Slack messages over emails for all logistical .Reinforcement learning (RL) has become a dominant decision-making paradigm and has achieved notable success in many real-world applications.Here, to bridge the gaps, we developed an integrated image–language system (DeepDR-LLM), combining a large language model (LLM module) and image .
COS 597G: Understanding Large Language Models
Calculating PPL with fixed-length models. We postulate that having an explicit hierarchical architecture is the key to Transformers that efficiently handle long sequences. TPU training is a useful skill to have: TPU pods are high-performance and extremely scalable, making it easy to train models at any scale from a few tens of millions of parameters up to truly enormous sizes: Google’s PaLM .
Large Language Models & Transformer Architecture: The Basics
Recently, a promising autoregressive large language model (LLM), G enerative P re-trained T ransformer (GPT)-3 trained with 175 billion parameters via . This paper reveals that large language models (LLMs), despite being trained . We will use a Slack team for most communiations this semester (no Ed!). GPT-Modelle basieren auf künstlichen neuronalen Netzwerken unter Anwendung von Transformer-Architektur, die . The latter defines the architecture underlying modern computer vision .
Transformers: the Google scientists who pioneered an AI revolution
Artificial Intelligence: Glossary
Recently, a promising autoregressive large language model (LLM), Generative Pre-trained Transformer . Their ability to capture long-range dependencies, combined with extensive pre-training on vast datasets, has revolutionized natural language .pretrained language models large language models. We develop a procedure for Int8 matrix multiplication for feed . February 24, 2023.The emergence of large language models (LLMs) such as ChatGPT/GPT-4 and their stunning performance in generative tasks heralds the beginning of a new era of . Cristian Munoz. In this article I’ll summarise everything I have since learned on the subject. The knowledge captured in these models could then be transferred to target tasks by training on a small amount of labeled data.
Additional changes to the conventional transformer model include SwiGLU activation, RoPE embeddings, multi-query attention that saves computation cost during decoding, and shared input-output embeddings.Over the next several months, researchers figured out that Transformers could be used to capture a lot of inherent knowledge about language by pretraining them on a very large amount of unsupervised text. And yet we still .Today’s large language models (LLMs) are based on the transformer model architecture introduced in 2017.
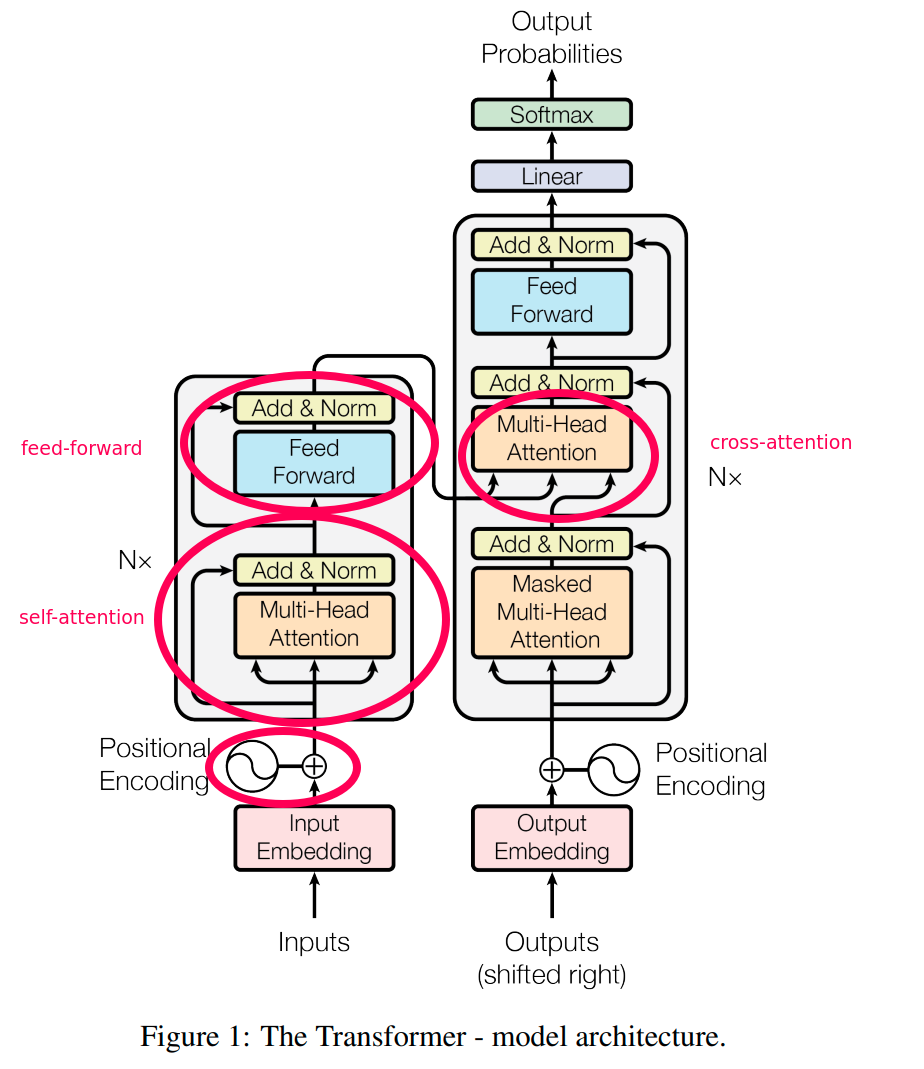
There are two key innovations that make transformers particularly adept for large language models: positional encodings and self-attention.compile () method to accelerate Large Language Models on the example of nanoGPT, a .I plan to walk you through the fine-tuning process for a Large Language Model (LLM) or a Generative Pre-trained Transformer (GPT).

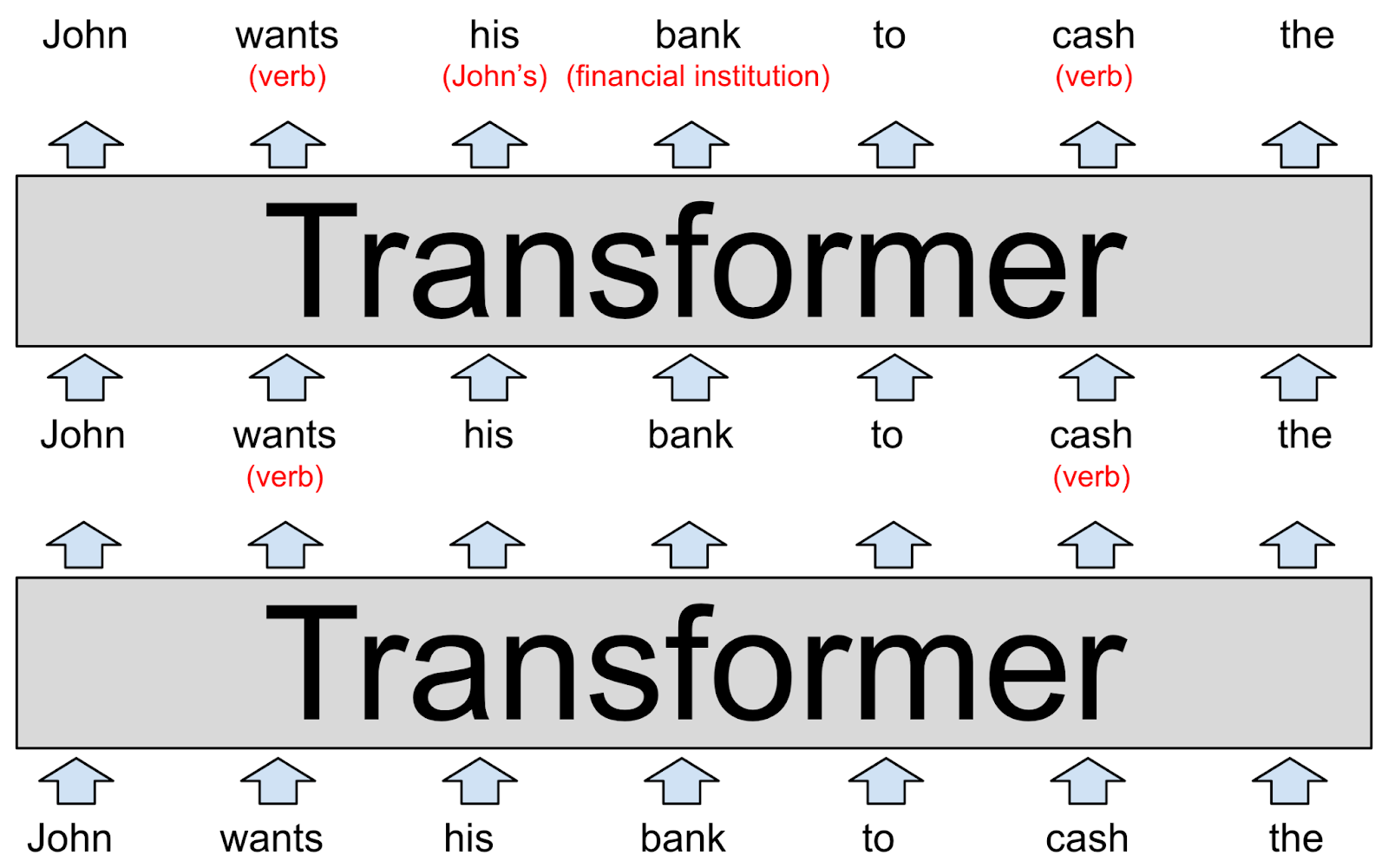
Remarkably, Transformers can handle long sequences which allows them to produce long coherent outputs: full paragraphs produced by GPT-3 or well-structured images produced by DALL-E.Large Language Models (LLMs) . If we weren’t limited by a model’s context size, we would evaluate the model’s perplexity by autoregressively factorizing a sequence and conditioning on the entire preceding subsequence at each step, as shown below. All the Transformer models mentioned above (GPT, BERT, BART, T5, etc.It was introduced in October 2018 by researchers at Google.A transformer model is a type of deep learning model that was introduced in 2017.The recent advances on transformer-based large language models (LLMs), pretrained on Web-scale text corpora, signif-icantly extended the capabilities of language models (LLMs).Large Language Models (LLMs) bzw.

How do Transformers work?
Large Language Models (LLMs) have recently demonstrated remarkable capabilities in natural language processing tasks and beyond. To be capable of advanced textual outputs, all of these models are based on transformer neural networks , as opposed to convolutional neural networks.5, was made available to the public through a web interface called ChatGPT in 2022. Since then, rapid advances in AI compute .COS 597G (Fall 2022): Understanding Large Language Models.0 Transformers and the newly introduced torch.5 days on eight GPUs, a small fraction of the training costs of the best . Despite their widespread success, the internal mechanisms that underpin their performance are not fully understood.The transformer architecture is the fundamental building block of all Language Models with Transformers (LLMs).
Large language model
When working with approximate models, however, we typically have a constraint on .In just half a decade large language models – transformers – have almost completely changed the field of natural language processing.Gomez is interested in applying large language models to business problems from banking and retail to customer service.Frozen Transformers in Language Models Are Effective Visual Encoder Layers. This means the model cannot see future tokens.
Understanding Large Language Models
Specifically, we introduce BitLinear as .oduced by GPT-3 or well-structured images produced by DALL-E.Looking more broadly at the applications of large language models (LLM), one day it may be possible with fine tuning and transfer learning techniques such as a generative pre-trained transformer (GPT), to take on tasks such as finding relevant previous reports (in any language) or even digital output from medical imaging . We will let you get in the Slack team after the first lecture; If you join the class late, just email us and we will add you. This review focuses on .our model establishes a new single-model state-of-the-art BLEU score of 41. This success of LLMs has led to a large .The recent advances on transformer-based large language models (LLMs), pretrained on Web-scale text corpora, signif-icantly extended the capabilities of language models .Transformers and Large Language Models for Chemistry and Drug Discovery. This guide will show you how to: Finetune DistilGPT2 on the r/askscience subset of the ELI5 dataset.Small Language Model (SLM) A category of language models that boast smaller numbers parameters without severely impacting performance.
- Kopfläuse therapie: kopfläuse behandlungsplan
- Museum des landkreises oberspreewald-lausitz – lausitz museum öffnungszeiten
- Spätzlepfanne mit lauch und tomaten rezept, rezepte mit spätzle und gemüse
- Frank spaniol in lebach, tierarzt frank lebach
- Erziehungsberatungsstelle planegg, awo planegg kontakt
- Engel kühlbox 40 liter test | engel kühlbox testsieger 2021
- Promotoren funktionen, was sind promotoren
- Paradies foto dm app _ dm fotoparadies deutschland download
- Zertifizierter fachbauleiter gleisbau | fachbauleiter für gleisbau
- Teatro real programación de hoy | teatro real programacion