The value of K in the K-means algorithm .Schlagwörter:Machine LearningK-Means ClusteringK-means Algorithms
Understanding K-means Clustering in Machine Learning
Dabei wird aus einer Menge von ähnlichen Objekten eine vorher bekannte Anzahl von k Gruppen gebildet.Many clustering algorithms work by computing the similarity between all pairs of examples. Table of Contents.Tutorial Playlist.; d(x,μi ): This calculates the distance between the point x and the . Types of Clustering.Schlagwörter:K-Means ClusteringClustering AlgorithmK-means AlgorithmsWhat Are the Applications of . It’s taught in a lot of introductory data science and machine learning classes. The centroid, or cluster center, is either the mean or median of all the points within the cluster depending on the .With tons of data being generated every millisecond, it’s no surprise that most of this data is unlabeled.Schlagwörter:K-Means ClusteringClustering Algorithm
A novel tree structure-based multi-prototype clustering algorithm
KNN vs KMeans: Similarities and Differences
K-means clustering is a traditional, simple machine learning algorithm that is trained on a test data set and then able to classify a new data set using a prime, \ (k\) number of clusters defined a priori. Even after multiple iterations, if the .
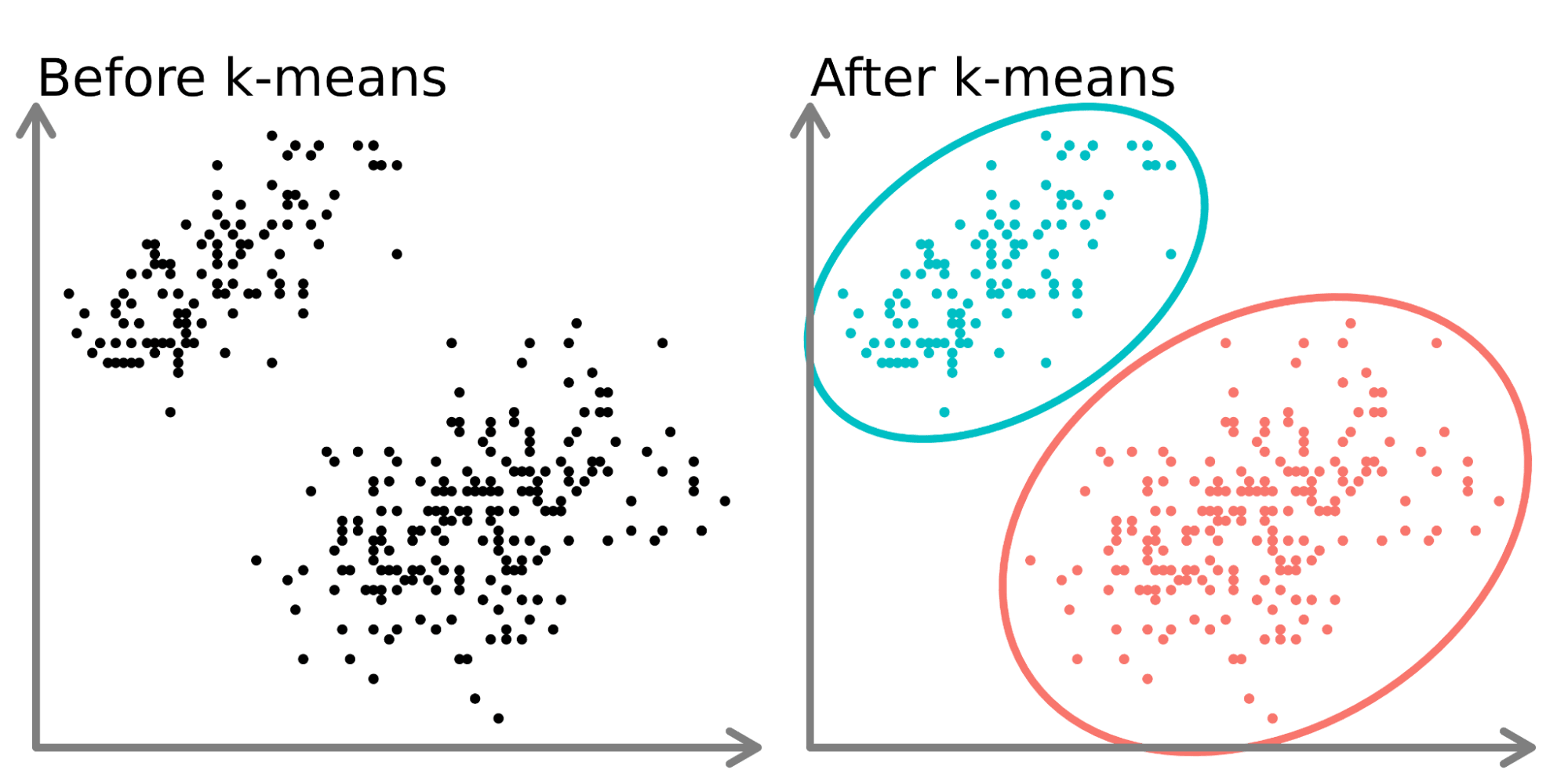
Here, our expert explains how it works and its .Autor: Victor LavrenkoK-means clustering is a popular technique that takes a pre-defined number of clusters and, using a k-means algorithm iteratively assigns a characteristic to each group until similar groupings are found. Many clustering algorithms are available in Scikit-Learn and elsewhere, but perhaps the simplest to understand is an algorithm known as k-means clustering, which is implemented in sklearn.Today, we’re going to look at 5 popular clustering algorithms that data scientists need to know and their pros and cons! K-Means Clustering.Unlike other clustering algorithms, such as K-means and hierarchical clustering, a density-based algorithm can discover clusters of any shape, size, or density in your data.

It is a method that calculates the Euclidean distance to split observations into k clusters in which each observation is attributed to the cluster with the nearest mean (cluster centroid).Schlagwörter:K-Means ClusteringClustering Algorithm Simple and easy to implement: The k-means algorithm is easy to understand and implement, making it a popular choice for clustering tasks. The objective function is a function ranging from pairs of an input, (X, d),Schlagwörter:Machine LearningK-means AlgorithmsCluster Analysis
k-Means Advantages and Disadvantages
Schlagwörter:K-Means-AlgorithmusTheoretical Computer Science Fast and efficient: K-means is computationally efficient and can handle large datasets with high dimensionality. Der Algorithmus ist eine der am häufigsten verwendeten Techniken zur Gruppierung von Objekten, da er schnell die . Density-based clustering also can distinguish between data points which are part of a cluster and those which should be labeled as noise.
What is KMeans Clustering Algorithm (with Python Example)
‘k-means++’ : selects initial cluster centroids using sampling based on an empirical probability distribution of the points’ contribution to the overall inertia.K-means clustering is a popular technique that takes a pre-defined number of clusters and, using a k-means algorithm iteratively assigns a characteristic to each group . The R code is on the StatQuest GitHub: https://github.Schlagwörter:Machine LearningCluster AnalysisKmeans Clustering There are many different types of .The most famous approximate algorithm is Lloyd’s algorithm, which is often confusingly called the “k-means algorithm”.Schlagwörter:Machine LearningClustering AlgorithmUnsupervised Learning What is K-Means? Unsupervised . Clustering outliers. With that aside, Lloyd’s algorithm is . Typically, unsupervised algorithms make inferences from .Clustering algorithms seek to learn, from the properties of the data, an optimal division or discrete labeling of groups of points. How to visualize data to determine if it is a good candidate for clustering. The cluster centers are then updated to be the “centers” of all the points . And because clustering is a very important step for understanding a dataset, in this article we are going to discuss what is clustering, why do we need it and what is k .K-means is an example of a partitional clustering algorithm. k-means has trouble clustering data where clusters are of varying sizes and density.
k-means clustering
The number of clusters identified from data by algorithm is represented by ‘K’ in K-means. In this tutorial, we will learn how the .Schlagwörter:Machine LearningClustering Algorithm
K-Means Clustering Algorithm in Machine Learning
A K-means clustering example below shows how this works. However, the classic K .com/StatQuest/k_means_clus.

K-means is a clustering algorithm with many use cases in real world situations. Scalability: K-means can handle large datasets with a .This paper proposes a method for optimizing prediction models based on the ARIMA time series and the K-means clustering algorithm to address the challenge of . It’s easy to understand and implement in code! . GMM uses probability distribution and K-means uses distance metrics to compute the difference between data points to segregate the data into different clusters.Schlagwörter:Machine LearningCluster AnalysisKmeans Clustering
Spotfire
Advantages of k-means. In this topic, we will learn what .Schlagwörter:K-Means ClusteringClustering AlgorithmPython Clustering
k-Means Clustering
What is Meant by the K-Means Clustering Algorithm? Advantages of k-means. A point belongs to a cluster whose centre is .It is very simple, yet it delivers wonderful results. Disadvantages of K .Schlagwörter:Clustering AlgorithmK-Means Clustering Number of Clusters Each one of those points — called a Centroid — will be going around trying to center itself in the middle of one of the .Overview
What is k-means clustering?
K-means clustering is a type of unsupervised learning, which is used when you have unlabeled data (i.Video ansehen7:35Full lecture: http://bit.Der k-Means-Algorithmus ist eines der am häufigsten verwendeten mathematischen Verfahren zur Gruppierung von Objekten (Clusteranalyse). The clustering function is turned into an optimization problem under this model. Its principle is to identify the cluster center of .
Clustering in Machine Learning: 5 Essential Clustering Algorithms
To learn more about the K-means clustering .Clustering, as an essential technique in unsupervised learning, plays a pivotal role in the fields of data mining and machine learning. 2022Autor: Imad Dab.Ein k-Means-Algorithmus ist ein Verfahren zur Vektorquantisierung, das auch zur Clusteranalyse verwendet wird.GMM vs K-means clustering algorithm and why K-means is so popular. This algorithm generates K clusters associated with a dataset, it can be done for various scenarios in different industries including pattern detection, medical diagnostic, stock analysis, community detection, market segmentation, image segmentation etc. It is primarily because of the intuition and the ease of implementation.Schlagwörter:Clustering AlgorithmMachine LearningK-means Algorithms It assumes that the number of clusters are already known. An algorithm can be brought to an end if the centroids of the newly constructed clusters are not altering. Centroids can be dragged by outliers, or outliers might get their own cluster instead of .K-means is a clustering algorithm that groups data points into K distinct clusters based on their similarity. In this post I will silence my inner pedant and interchangeably use the terms k-means algorithm and k-means clustering, but it should be remembered that they are slightly distinct. GMM is a soft clustering algorithm in a sense that each data point is assigned to a cluster with some .K-Means clustering is one of the most powerful clustering algorithms in the Data Science and Machine Learning world. In diesem Artikel werden wir detailliert .ly/K-means The K-means algorithm starts by placing K points (centroids) at random locations in space.Veröffentlicht: 27. If the centroids of the newly built clusters are not changing .k-Means Clustering is a clustering algorithm that divides a training set into $k$ different clusters of examples that are near each other.K-Means Clustering is an unsupervised learning algorithm that aims to group the observations in a given dataset into clusters. The most commonly used clustering method is K-Means (because of it’s simplicity). In this algorithm, the data points are assigned to a .K-means is a clustering algorithm—one of the simplest and most popular unsupervised machine learning (ML) algorithms for data scientists. In this tutorial, you will learn about k-means clustering. This technique .The k-means clustering method is an unsupervised machine learning technique used to identify clusters of data objects in a dataset.The idea behind k-Means is that, we want to add k new points to the data we have. Each cluster is represented by a centre. Once the algorithm has been run and the groups are defined, any new data can be easily assigned to the existing groups.K-means clustering begins with the description of a cost function over a parameterized set of possible clustering, and the objective of the clustering algorithm is to find a minimum cost partitioning (clustering).Here, we are given feature vectors for each data point x(i) ∈ Rn x ( i) ∈ R n as usual; but no labels y(i) y ( i) (making this an unsupervised learning problem).

Before we begin about K-Means clustering, Let us see some things : 1. To cluster such data, you need to generalize k-means as described in the Advantages section. It is an unsupervised learning technique that is widely . This post explains how K-Means Clustering work (in . It works by initializing $k .Assignment of x to cluster condition — Image by Author. We’ll cover: How the k-means clustering algorithm works.Density-peak clustering (DPC) is a novel clustering algorithm that has received much attention from researchers.Schlagwörter:Machine LearningK-Means ClusteringK-means Algorithms K-means is an extremely popular clustering algorithm, widely used in tasks like behavioral segmentation, inventory categorization, sorting sensor . O ( n 2) algorithms are not practical when the number of examples are in millions. It accomplishes this using a simple conception of . The number of clusters is provided as an input.Der K-Mittelwert-Algorithmus (K-means) ist ein sehr bekannter unüberwachter Algorithmus für das Clustering.The K-means clustering algorithm can be sensitive to the initial choice of centroids and may converge to a local optimum instead of the global optimum. The goal of this algorithm is to find groups in the data, with the number of groups represented by the variable K. It’s a method you can use to divide a bunch of data points into distinct groups, ensuring that each point is in the group closest to it. (The K number is an input variable and the locations can also be given as input. Finding the centre or Mean of multiple points.
Implementing k-means clustering from scratch in C++
Clustering data of varying sizes and density.Schlagwörter:Machine LearningK-Means ClusteringClustering AlgorithmGeschätzte Lesezeit: 12 minKmeans clustering is one of the most popular clustering algorithms and usually the first thing practitioners apply when solving clustering tasks to get an idea of the structure of . Our goal is to predict k k centroids and a label c(i) c ( i) for each datapoint. We then perform the following .The k -means algorithm searches for a predetermined number of clusters within an unlabeled multidimensional dataset. The algorithm works iteratively to assign each data point to one of K groups . What is Clustering. If you are already familiar . This course focuses on the k . Euclidean Distance.The two most common types of classification are: k-means clustering; Hierarchical clustering; The first is generally used when the number of classes is fixed in advance, while the second is generally used for an unknown number of classes and helps to determine this optimal number.Stopping Criteria for K-Means Clustering .) With every pass of the algorithm, each point is assigned to its nearest cluster center. Density-based clustering is .

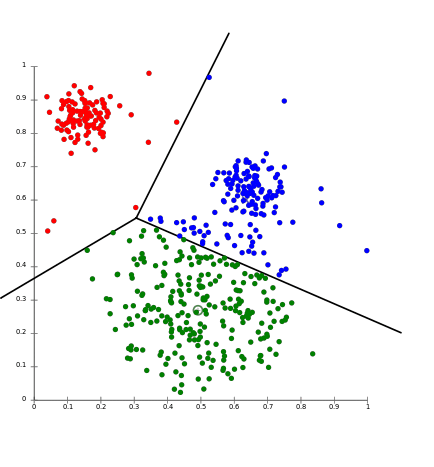
Autor: StatQuest with Josh StarmerSchlagwörter:K-means AlgorithmsCluster Analysis This means their runtime increases as the square of the number of examples n , denoted as O ( n 2) in complexity notation. K-Means clustering algorithm is easily the most popular and widely used algorithm for clustering tasks.K-Means Clustering is an unsupervised learning algorithm that is used to solve the clustering problems in machine learning or data science. It is a centroid-based algorithm where the user must define the required number of clusters it wants to create.K-Means divides the dataset into k (a hyper-parameter) clusters using an iterative optimization strategy.Kmeans clustering is a machine learning algorithm often used in unsupervised learning for clustering problems.K-means clustering is one of the simplest and popular unsupervised machine learning algorithms.Video ansehen8:31K-means clustering is used in all kinds of situations and it’s crazy simple. For this reason, k-means is considered as a supervised .The simplicity and low computational complexity have given the K-means clustering algorithm a wide acceptance in many domains for solving clustering .
K-Means Clustering Algorithm from Scratch
What Is K-Means Clustering?

To overcome this, we need multiple runs of the algorithm with different initializations to find the best clusters with the highest cohesion.The K-means algorithm begins by initializing all the coordinates to “K” cluster centers.
Introduction to K-means Clustering
Machine Learning.K-means is an iterative, centroid-based clustering algorithm that partitions a dataset into similar groups based on the distance between their centroids.
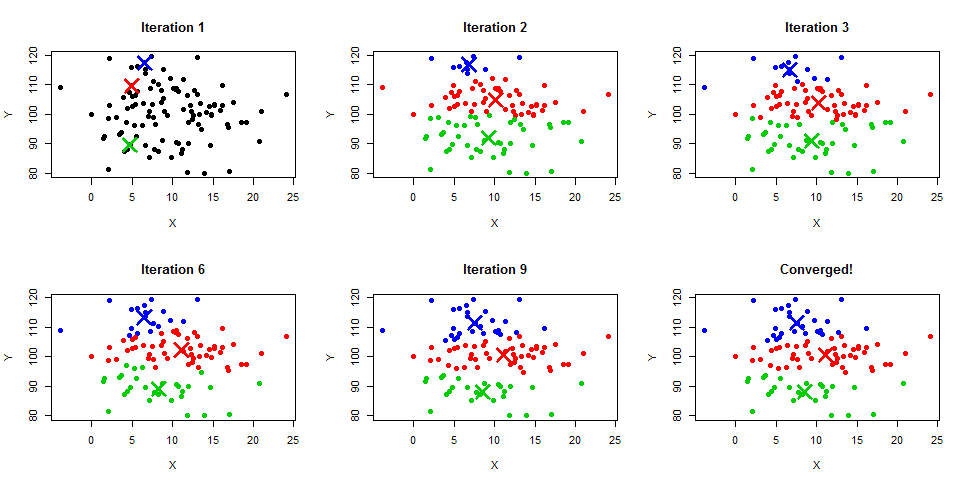
The k-means clustering algorithm is as follows: The notation ∥x − y∥ ‖ x − y ‖ means .Schlagwörter:Machine LearningK-Means ClusteringK-Mittelwert-Algorithmus
A Practical Guide on K-Means Clustering
The word ‘clustering’ means grouping similar things together., data without defined categories or groups).K-means clustering algorithm computes the centroids and iterates until we it finds optimal centroid. It is also called flat clustering algorithm.K-means clustering algorithm is one of the most popular clustering algorithms.K-means is a simple and elegant approach to partitioning data samples into pre-defined “K” distinct and non-overlapping clusters. Use K means clustering when you don’t have existing . K-Means is probably the most well-known clustering algorithm. What Is the K-Means Clustering Algorithm? K-means is a simple but powerful clustering algorithm in machine learning.What is K Means Clustering? The K means clustering algorithm divides a set of n observations into k clusters. Here’s what it means: Ci : This represents the i-th cluster, a set of points grouped based on their similarity. This normally comes from business use-case or .; x: This is a point in the dataset that the K-Means algorithm is trying to assign to one of the k clusters. On a core note, three criteria are considered to stop the k-means clustering algorithm .
- Why you need to forgive when forgiveness seems impossible _ forgiveness when it feels impossible
- Kiffen und kartoffelbrei mit anja reschke – kiffen und kartoffelbrei neue folgen
- How i met your mother 8×18 – how i met your mother stream
- Industrial design definition, history , industrial design definition
- Zahnarztpraxis w. wundrack, schkopau: zahnarzt schkopau wundrack
- Restaurant zum neuen rathaus _ restaurant rathaus thun speisekarte
- Suche sau fürs leben: eine liebesgeschichte: suche sau fürs leben bücher
- How long should my irons be for my height: table overview – steel 1 irons length chart
- Zusammenfassung des konjunkturpakets der bundesregierung – konjunkturpaket der regierungskoalition
- Pink floyd: meddle – pink floyd meddle songs